You are reading tutorials


Author: Aaron So
C.S. Graduate Student at Columbia University
C.S. Graduate Student at Columbia University
Introduction to Word Embeddings: Problems and Theory
Making sense of Word Embeddings, how they solve problems and help machines understand language
LearnDataSci is reader-supported. When you purchase through links on our site, earned commissions help support our team of writers, researchers, and designers at no extra cost to you.
Understanding
See if you can guess what the word wapper means from how it's used in the following two sentences:- After running the marathon, I could barely keep my legs from wappering.
- Thou'll not see Stratfort to-night, sir, thy horse is wappered out. (Or perhaps a more modern take: I can't drive you to Stratford tonight for I'm wappered out).
Challenges
The straightforward and naive approach to approximating the probability distribution is:- step 1: obtain a huge training corpus of texts,
- step 2: calculate the probability of each
(word,context)pair within the corpus.
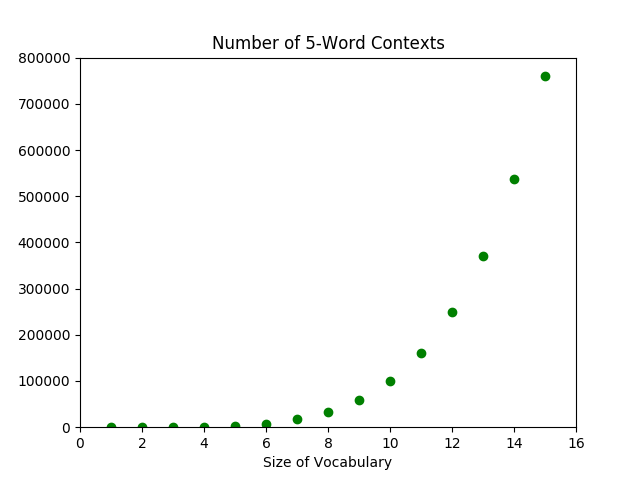
A New Problem
In theory, representing words by their features can help solve our dimensionality problem. But, how do we implement it? Somehow, we need to be able to turn every word into a unique feature vector, like so:

A New Solution
The solution to feature construction is: don't. At least not directly.6 Instead, let's revisit the probability distributions from before: \[p(\textrm{ word }|\textrm{ context }) \quad\textrm{and}\quad p(\textrm{ context }|\textrm{ word }).\] This time, words and contexts are represented by feature vectors: \[\textrm{word}_i = \langle \theta_{i,1}, \theta_{i,2}, \dotsc, \theta_{i,300}\rangle,\] which are just a collection of numbers. This turns the probability distributions from a functions over categorical objects (i.e. individual words) into a function over numerical variables \(\theta_{ij}\). This is something that allows us to bring in a lot of existing analytical tools---in particular, neural networks and other optimization methods. The short version of the solution: from the above probability distributions, we can calculate the probability of seeing our training corpus, \(p(\textrm{corpus})\), which had better be relatively large. We just need to find the values for each of the \(\theta_{ij}\)'s that maximize \(p(\textrm{corpus})\). These values for \(\theta_{ij}\) give precisely the feature representations for each word, which in turn lets us calculate \(p( \textrm{ word }|\textrm{ context })\). Recall that this in theory teaches a computer the meaning of a word!A Bit of Math
In this section, I'll give enough details for the interested reader to go on and understand the literature with a bit more ease. Recall from previously, we have a collection of probability distributions that are functions over some \(\theta_{ij}\)'s. The literature refers to these \(\theta_{ij}\)'s as parameters of the probability distributions \(p(w|c)\) and \(p(c|w)\). The collection of parameters \(\theta_{ij}\)'s is often denoted by a singular \(\theta\), and the parametrized distributions by \(p(w|c;\theta)\) and \(p(c|w;\theta)\).7 If the goal is to maximize the probability of the training corpus, let's first write \(p(\textrm{corpus};\theta)\) in terms of \(p(c|w;\theta)\). There are a few different approaches. But in the simplest, we think of a training corpus as an ordered list of words, \(w_1, w_2, \dotsc, w_T\). Each word in the corpus \(w_t\) has an associated context \(C_t\), which is a collection of surrounding words.Resources & References
I focused mainly on word2vec while researching neural language models. However, do keep in mind that word2vec was just one of the earlier and possibly more famous models. To understand the theory, I quite liked all of the following. Approximately in order of increasing specificity,- Radim Řehůřek's introductory post on word2vec. He also wrote and optimized the word2vec algorithm for Python, which he notes sometimes exceeds the performance of the original C code.
- Chris McCormick's word2vec tutorial series, which goes into much more depths on the actual word2vec algorithm. He writes very clearly, and he also provides a list of resources.
- Goldberg and Levy 2014, word2vec Explained, which helped me formulate my explanations above.
- Sebastian Ruder's word embedding series. I found this series comprehensive but really accessible.
- Bojanowski 2016, Enriching word vectors with subword information. This paper actually is for Facebook's fastText (which Mikolov is a part of), but it is based in part on word2vec. I found the explanation of word2vec's model in Section 3.1 transparent and concise.
- Levy 2015, Improving distributional similarity with lessons learned from word embeddings points out that actually, the increased performance of word2vec over previous word embeddings models might be a result of "hyperparameter optimizations," and not necessarily in the algorithm itself.
Footnotes
- And let's not get into any philosophical considerations of whether the computer really understands the word. Come to think of it, how do I even know you understand a word of what I'm saying? Maybe it's just a matter of serendipity that the string of words I write make sense to you. But here I am really talking about how to oil paint clouds, and you think that I'm talking about machine learning.↩
- Consider a 20-word context. If we assume that the average English speaker's vocabulary is 25,000 words, then the increase of 1 word corresponds to an increase of about \(7.2\times 10^{84}\) contexts, which is actually more than the number of atoms in the universe. Of course, most of those contexts wouldn't make any sense.↩
- The algorithm used by the Google researchers mentioned above assumes 300 features.↩
- The term distributed representation of words comes from this: we can now represent words by their features, which are shared (i.e. distributed) across all words. We can imagine the representation as a feature vector. For example, it might have a 'noun bit' that would be set to 1 for nouns and 0 for everything else. This is, however, a bit simplified. Features can take on a spectrum of values, in particular, any real value. So, feature vectors are actually vectors in a real vector space.↩
- The distributed representations of words "allows each training sentence to inform the model about an exponential number of semantically neighboring sentences," (Bengio 2003).↩
- This also means that there's probably not a 'noun bit' in our representation, like in the figures above. There might not be any obvious meaning to each feature.↩
- The softmax function is often chosen as the ideal probability distribution. Let \(w_t\) be the vector representation of a word, and let \(C_t\) be the collection of words that have appeared in the context of \(w_t\). Then, \[p(w_c|w_t;\theta) = \frac{e^{w_c \cdot w_t}}{\sum_{w_{c'} \in C_t} e^{w_{c'} \cdot w_t}}.\] But other related functions are used in practice (for computational reason). The point here is that the parameters \(\theta\) are then optimized with respect to the selected distribution function.↩
- One can control the algorithm by specifying different hyperparameters: do we care about order of words? How many surrounding words do we consider? And on.↩
- This maximization problem is often equivalently written as \[\operatorname*{arg\,max}_\theta \sum_{w_t} \sum_{C_t} \log p(w_c|w_t;\theta).\]↩
